Allocation-Free GroupBy in .NET

Grouping data is a common operation in .NET, and the standard approach is to use LINQ’s GroupBy. While convenient, GroupBy allocates memory for each group, which can become a performance bottleneck in high-throughput or low-latency scenarios. The memory usage is not fixed; large collections can introduce significant overhead.
In this article, we’ll explore alternatives to LINQ’s GroupBy that avoid these allocations while preserving (or mimicking) the same behavior.
To better isolate the issue, we’ll use a simple example. While it may not reflect real-world complexity (and micro-benchmarking always comes with caveats); it serves well for measuring memory usage and allocations, helping us understand the implications of different approaches.
NOTE: LINQ’s
OrderByis implemented as an extension toIEnumerable<T>, allowing it to operate on both concrete collections and lazily evaluated data streams. In this article, we focus on the special case where theIEnumerablesource is a concrete collection, which enables allocation-free optimizations not possible with general lazy streams.
Option 1: LINQ GroupBy
This example serves as our baseline. The calculation is minimal, and we use only GroupBy from LINQ to isolate its effects. The input is a List, which we pass as-is to avoid introducing extra allocations that could skew results.
LINQ’s GroupBy is elegant and expressive, and it should remain your go-to in most cases, unless you’re on a hot path where allocations matter.
1
2
3
4
5
public class Foo
{
public int Number { get; set; }
public int GroupBy { get; set; }
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
public class Option1(List<Foo> foos)
{
private readonly List<Foo> _foos = foos;
public long Calculate()
{
long result = 1;
foreach (var group in _foos.GroupBy(f => f.GroupBy))
{
var sum = 0;
foreach (var foo in group)
{
sum += foo.Number;
}
result *= sum;
}
return result;
}
}
- Allocates: Yes (per group)
- Performance: Baseline
Option 2: Sort and Slice with ArrayPool
If you’re in a performance-critical scenario, Option 1 may not be suitable. A viable alternative is to sort the collection by the grouping key so that identical keys are placed contiguously. Then, we simply “slice” the contiguous segments and process them.
This mimics what GroupBy does internally, it finds all items in the group and serves them to you as a single sequence. To preserve the same behavior, we’re not altering the internal List<Foo>; we copy its contents into a rented array using ArrayPool.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
public class Option2(List<Foo> foos)
{
private readonly List<Foo> _foos = foos;
public long Calculate()
{
long result = 1;
var array = ArrayPool<Foo>.Shared.Rent(_foos.Count);
try
{
_foos.CopyTo(array, 0);
var span = array.AsSpan(0, _foos.Count);
span.Sort((x, y) => x.GroupBy.CompareTo(y.GroupBy));
var groupStart = 0;
for (var i = 1; i <= span.Length; i++)
{
// If we reached the end of the span or the group has changed, we slice and process the group.
if (i == span.Length || span[i].GroupBy != span[groupStart].GroupBy)
{
result *= SumGroup(span[groupStart..i]);
groupStart = i;
}
}
}
finally
{
ArrayPool<Foo>.Shared.Return(array);
}
return result;
static long SumGroup(ReadOnlySpan<Foo> group)
{
long sum = 0;
foreach (var foo in group)
{
sum += foo.Number;
}
return sum;
}
}
}
- Allocates: No (uses pooled array)
- Performance: Slower for large collections (sorts a copy each time), but comparable.
Option 3: Keep Sorted and Slice
This option is not equivalent in behavior; it assumes more control over the internal collection. However, in many real-world scenarios, it would be acceptable to keep the collections sorted if they aren’t mutated frequently.
If you can ensure the list is already sorted by the grouping key, either by using SortedList, custom insertion logic, or by sorting once upfront; you can avoid both allocations and sorting during computation.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
public class Option3(List<Foo> foos)
{
private readonly List<Foo> _foos = foos;
public long Calculate()
{
long result = 1;
var span = CollectionsMarshal.AsSpan(_foos);
var groupStart = 0;
for (var i = 1; i <= span.Length; i++)
{
// If we reached the end of the span or the group has changed, we slice and process the group.
if (i == span.Length || span[i].GroupBy != span[groupStart].GroupBy)
{
result *= SumGroup(span[groupStart..i]);
groupStart = i;
}
}
return result;
static long SumGroup(ReadOnlySpan<Foo> group)
{
long sum = 0;
foreach (var foo in group)
{
sum += foo.Number;
}
return sum;
}
}
}
- Allocates: No
- Performance: Fastest (no copy, no sort, no allocation)
- Caveat: You must keep the list sorted by the grouping key
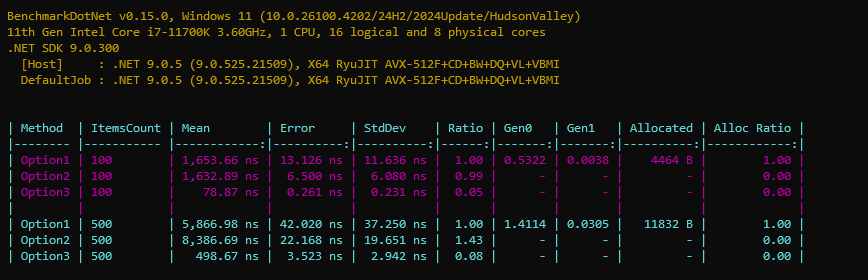
Benchmark Results
We’ve reduced allocations from thousands of bytes down to zero. Option 2 is slower for larger collections due to sorting, but remains close in performance. In real workloads with heavier per-group operations, the performance difference would likely be negligible and statistically insignificant.
Option 3 is significantly faster, though not equivalent, the original list must be sorted beforehand, and it’s not part of the benchmark.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
[MemoryDiagnoser]
public class Benchmark
{
private Option1 _option1 = null!;
private Option2 _option2 = null!;
private Option3 _option3 = null!;
[Params(100, 500)]
public int ItemsCount { get; set; }
[GlobalSetup]
public void Setup()
{
var random = new Random(111);
var foos = Enumerable.Range(0, ItemsCount).Select(i => new Foo
{
Number = i,
GroupBy = random.Next(1, 10)
}).ToList();
_option1 = new Option1(foos.ToList());
_option2 = new Option2(foos.ToList());
_option3 = new Option3(foos.OrderBy(x=>x.GroupBy).ToList());
}
[Benchmark(Baseline = true)]
public long Option1() => _option1.Calculate();
[Benchmark]
public long Option2() => _option2.Calculate();
[Benchmark]
public long Option3() => _option3.Calculate();
}
Summary
- Option 1 is simple and idiomatic, but incurs allocations per group (significant for larger collections).
- Option 2 eliminates allocations using ArrayPool, at the cost of sorting and copying.
- Option 3 is the most efficient, with zero allocations and minimal processing, if you can guarantee a pre-sorted list.
I hope you found this article useful. Happy coding!
Comments powered by Disqus.